By Elavarasan P
Natural Language processing (Basics to SOTA models) – Part-1
Introduction
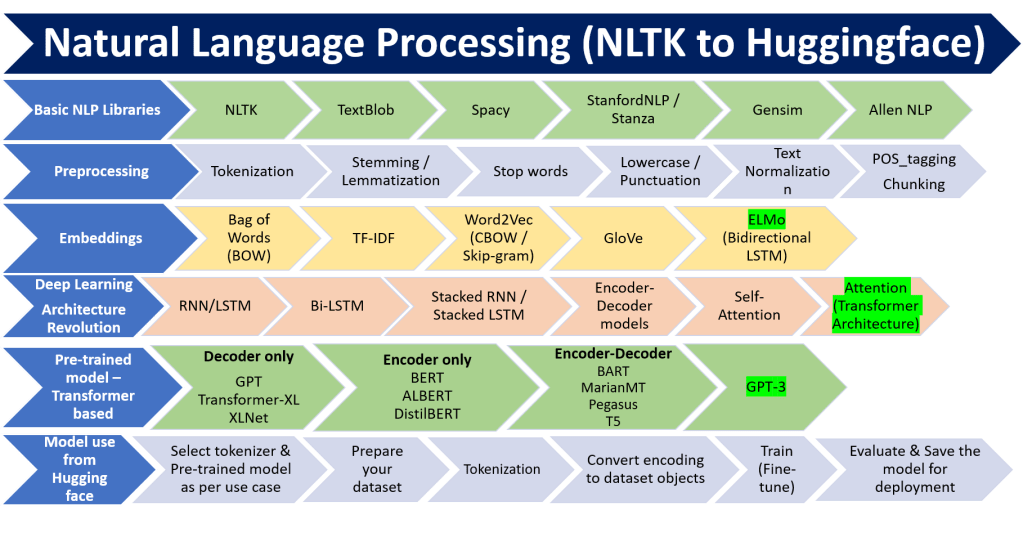
This article provides the complete overview of Natural Language processing starting from use cases, basic NLP Libraries, preprocessing, embeddings, deep learning techniques used, Transformers (Attention mechanism) based SOTA models and how to use these models from huggingface libraries. Transformer based models have given a revolution in NLP. But, context creation is still a challenge when the sentence length increases. My idea is to provide examples to understand the concepts easily rather than explaining in detail.
Embeddings are the inputs for most of the NLP tasks. There are different ways of converting text into numeric form ranging from large sparse vectors to small dense vector representation.
- Part-1 of this blog covers topics till embedding.
- Part-2 will cover various Deep learning architectures, Pre-trained models and sample Huggingface implementation
NLP use cases:
| Category | Use case | Examples |
|---|---|---|
| Generate new sentence from input text | a) Machine translation b)Text summarization | a) Translation from English to French b) inshorts news summary |
| Text classification | a) Spam b) Sentiment classification | a) Gmail spam folder b) customer sentiment in terms of positive, negative and Neutral |
| Classify each word in a sentence | a) NER b) POS Tagging | a) Identifying Person, Organization, location in a sentence b) Noun, verb identification |
| Natural Language inferencing | Recognizing textual entailment |  |
There are many such use cases
- Question Answering
- Fill in the blanks
- sentence completion
- Autocorrect
- auto completion (Gmail)
To get idea on industry wise use cases, visit here
Real time example: There are many real-world examples like News summary, Grammarly, Alexa, Google translate, chatbots, etc.
Extraction of Contractual terms use case, go here. Given a contract document, how do we extract agreement name, start date, End date, renewal term, parties involved, Termination for Convenience, audit rights, insurance, Liquidated damages, etc. This becomes important for larger organization which has many contracts with various vendors.
Approaches to NLP
There are below three approaches to NLP
- Heuristic (Rule based)
- Regular Expressions, wordnet
- Machine Learning
- Naïve Bayes, SVM, Logistic regression, LDA, Hidden Markov Model
- Deep Learning (RNN, LSTM, GRU, Transformers)
- Both Machine learning and Rule based approaches works on word level. They don’t address the sentence level NLP tasks in terms of context between 2 sentences and the sequence of words in a sentence. There are still improvements needed in understanding context and ambiguity using deep learning methods when the sentence length increases.
Basic NLP Libraries
This section provides the list of basic libraries, NLP tasks that can be done, whether it is derived from neural network and Areas where they are suitable
| Library | NLP Tasks | Neural Network | Best for | Unique features |
|---|---|---|---|---|
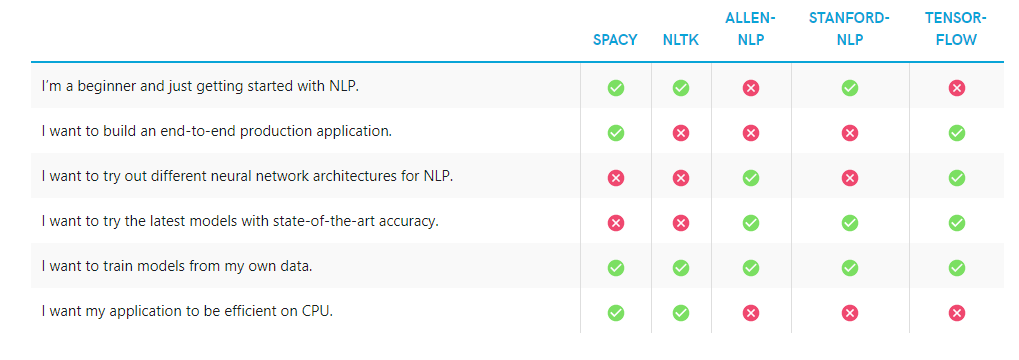
| NLTK | tokenization, stemming, tagging, parsing | No | Training, Education, Research | Multilingual support 50 Corpora |
| TextBlob | POS Tagging, noun phrase extraction sentiment analysis, classification, translation | No | NLP prototyping | Translation Spelling correction |
| Gensim | Test similarity summarization, Topic modelling | No | converting words and sentences into vectors | Scalability, High performance |
| Spacy | Tokenization, CNN tagging, parsing, NER, classification, Sentiment analysis | Yes | Business, production | 50+ languages available for tokenization |
| StanfordNLP /Stanza | Dependency parsing Sentiment NER | Yes | Production grade | Statistical models |
Comparison of NLP libraries in terms of when to use them
Text Preprocessing
Tokenization
It is a way of separating a piece of text into smaller units called tokens, such as sentence, word, sub-word and characters.
| Types of Tokenization | Meaning | Input | Output |
|---|---|---|---|
| sentence | Split a paragraph into individual sentence | Natural language processing is one of the fields in programming where the natural language is processed by the software. This has many applications like sentiment analysis, language translation, fake news detection, grammatical error detection etc | Natural language processing is one of the fields in programming where the natural language is processed by the software. This has many applications like sentiment analysis, language translation, fake news detection, grammatical error detection etc |
| word | splits a piece of text into individual words based on a certain delimiter | work hard. Never give up | work hard Never give up |
| Subword | splits the piece of text into subwords (or n-gram characters). | smarter | smart |
| character | splits a piece of text into a set of characters | smarter | S | m | a | r | t | e | r |
Stemming:
Stemming just removes or stems the last few characters of a word, often leading to incorrect meanings and spelling
| Input | Output |
|---|---|
| Change Changes Changed changing | Chang |
| studying studied studies | studi |
| was | wa |
Lemmatization
It considers the context and converts the word to its meaningful root form. This operation slower than stemming.
| Input | Output |
|---|---|
| Change Changes Changed changing | Change |
| studying studied studies | study |
| was | be |
Text Normalization
The process of transforming text into a single canonical / standard form
| Input | Output |
|---|---|
| 2moro 2mrrw 2morrow 2mrw tomrw | tomorrow |
| b4 | before |
| otw | on the way |
POS Tagging
The Part of Speech (POS) explains how a word is used in a sentence. There are eight main parts of speech – nouns, pronouns, adjectives, verbs, adverbs, prepositions, conjunctions and interjections. In fact , there are 36 tags in combination
| Input | Output |
|---|---|
| I like to read books | I-PRP like-VBP to – TO read-VB (Verb) books-NNS (Noun-plural) |
Chunking:
It extracts phrases from unstructured data and give structure to it. It uses POS-tags as input and provides chunks as output.

Stop words:
Stop words are actually the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and does not add much information to the text. Examples of a few stop words in English are “the”, “a”, “an”, “so”, “what”
Embeddings
Embedding methods (also called as encoding / vectorizing) convert symbolic representations (i.e. words, emojis, categorical items, dates, times, other features, etc) into meaningful numbers. Word embeddings are a way to represent words and whole sentences in a numerical manner.
a. Bag of words (BOW):
Bag of words is created based on number of times each word occurs in each of the document. In the below table, Row represents document ID and column represents the words.

b. TF-IDF:
Term frequency(TF) is calculated for all the words in each document (Word vs Doc). Inverse document frequency (IDF) is calculated for each word considering all the documents together. TFIDF value is generated for all the words in each document.
Document 1: Text processing is necessary.
Document 2: Text processing is necessary and important.
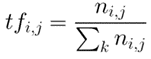
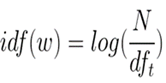

- TFIDF gives importance to uncommon words.
- There is a chance for overfitting
- Both BOW and TFIDF don’t store semantic (meaning) information
c) Word2Vec:
- In Word2vec, Each word is represented as a vector of 32 or more dimension instead of single number.
- Semantic information and relation between different words are preserved
Word2vec embeddings can be created using continuous bag of words (CBOW) and skip-gram models. Both are deep learning models.
i) CBOW:
consider the sentence – “Word2Vec has a deep learning model working in the backend.”, there can be pairs of context words and target (center) words. If we consider a context window size of 2, we will have pairs like ([deep, model], learning), ([model, in], working), ([a, learning), deep) etc. in the format – ([2 context words], target word) The deep learning model would try to predict these target words based on the context word. search word is represented as a vector of 32 or more dimension instead of single number.
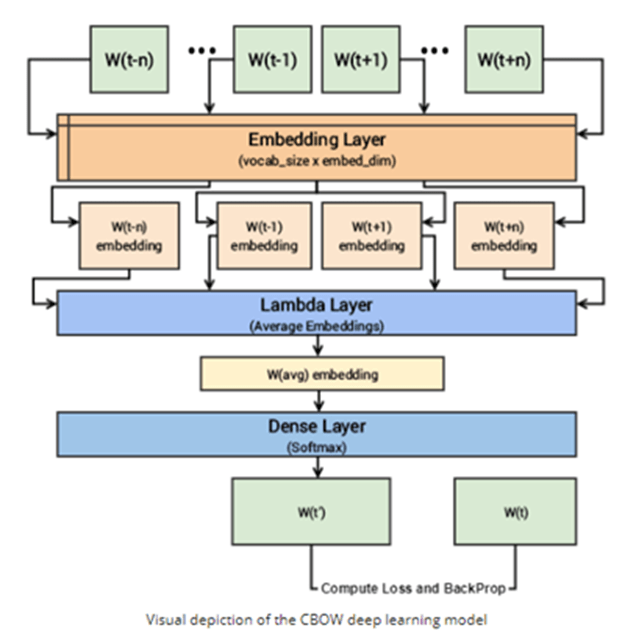
- The context words are first passed as an input to an embedding layer (initialized with some random weights) as shown in the Figure below.
- The word embeddings are then passed to a lambda layer where we average out the word embeddings.
- We then pass these embeddings to a dense SoftMax layer that predicts our target word. We match this with our target word and compute the loss and then we perform backpropagation with each epoch to update the embedding layer in the process.
- We can extract out the embeddings of the needed words from our embedding layer, once the training is completed.
ii) Skip-gram model:
In the skip-gram model, given a target (Centre) word, the context words are predicted. So, considering the same sentence – “Word2Vec has a deep learning model working in the backend.” and a context window size of 2, given the Centre word ‘learning’, the model tries to predict [‘deep’, ’model’]
Since the skip-gram model has to predict multiple words from a single given word, we feed the model pairs of (X, Y) where X is our input and Y is our label. This is done by creating positive input samples and negative input samples. Positive Input Samples will have the training data in this form: [(target, context),1] where the target is the target or Centre word, context represents the surrounding context words, and label 1 indicates if it is a relevant pair. Negative Input Samples will have the training data in the same form: [(target, random),0]. In this case, instead of the actual surrounding words, randomly selected words are fed in along with the target words with a label of 0 indicating that it’s an irrelevant pair.

- Both the target and context word pairs are passed to individual embedding layers from which we get dense word embeddings for each of these two words.
- We then use a ‘merge layer’ to compute the dot product of these two embeddings and get the dot product value.
- This dot product value is then sent to a dense sigmoid layer that outputs either 0 or 1.
- The output is compared with the actual label and the loss is computed followed by backpropagation with each epoch to update the embedding layer in the process.
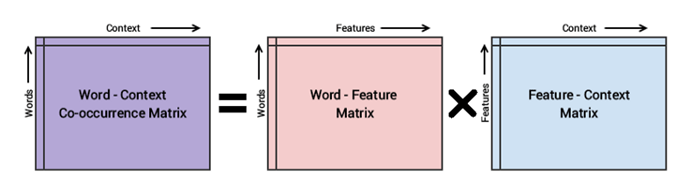
d) GloVe:
Glove model is based on leveraging global word to word co-occurrence counts leveraging the entire corpus. Word2vec on the other hand leverages co-occurrence within local context (neighboring words). Aims to combine the count-based matrix factorization and the context-based skip-gram model together.
GloVe focuses on capturing the similarity in context between words. It is lighter and more efficient than word2vec.
e) ELMo ( Embeddings from Language Models based on Bi-directional LSTM):
ELMo word vectors are computed on top of a two-layer bidirectional language model (biLM). This biLM model has two layers stacked together. Each layer has 2 passes — forward pass and backward pass.

- The architecture above uses a character-level convolutional neural network (CNN) to represent words of a text string into raw word vectors
- These raw word vectors act as inputs to the first layer of biLM
- The forward pass contains information about a certain word and the context (other words) before that word
- The backward pass contains information about the word and the context after it
- This pair of information, from the forward and backward pass, forms the intermediate word vectors
- These intermediate word vectors are fed into the next layer of biLM
- The final representation (ELMo) is the weighted sum of the raw word vectors and the 2 intermediate word vectors
Summary – Embeddings:

Challenges with BOW and TFIDF
- TFIDF gives importance to uncommon words.
- There is a chance for overfitting
- Both BOW and TFIDF don’t store semantic (meaning) information
Word2Vec addresses the above challenges
Challenges with Word2Vec
- Word2Vec is a window-based model, so it does not benefit from the information in the whole document
- it does not capture sub-word information, which could be interesting since adjectives are derived from nouns or verbs hold information in common.
- Also, Word2Vec can not handle Out Of Vocabulary words (OOV), since words not seen during the training can not be vectorized.
- Finally, an other problem that is not solved by Word2Vec is the disambiguation. A word can have multiple senses, which depend on the context.
The first three problems are addressed with GloVe and FastText – whole doc, sub-word information, OOV words
while the last one has been resolved with ELMo – – – disambiguation: Different meaning of same word in different context: words like fair, lie, bat, lead, minute, project, second give different meaning in different context.
Hope this blog provided an overview to start with. Part-2 of this NLP blog will cover various Deep learning architectures, Pre-trained models and sample Huggingface implementation
Some useful references
