By Elavarasan P
Natural Language processing (Basics to SOTA models) – Part-2
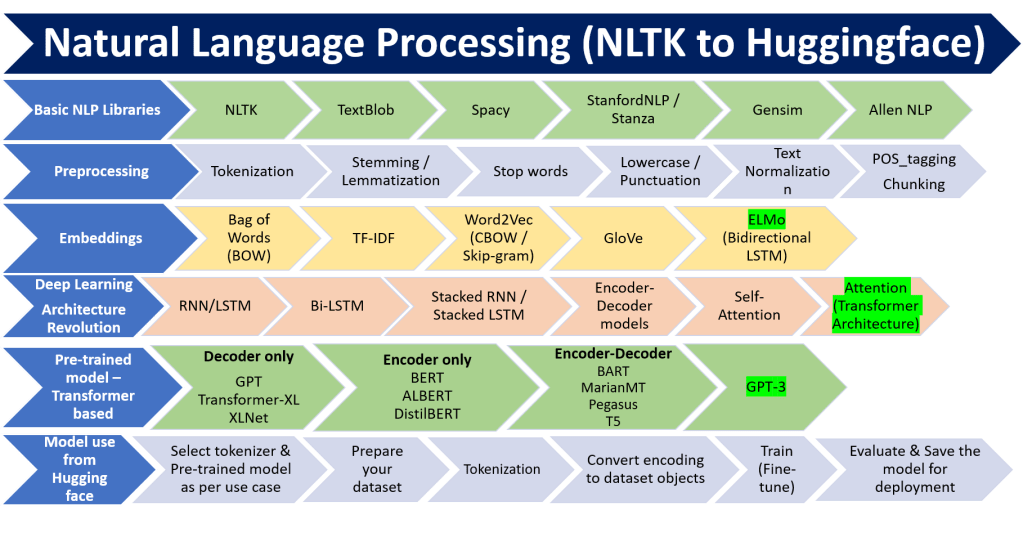
In part-1 of this post, we discussed about basic NLP libraries, preprocessing of text and embeddings. Here, In the second part, we provide an overview of different deep learning architecture transformer based pre-trained models and how huggingface can be used to solve an NLP task.
Deep Learning Architecture Revolution
Let us discuss about the deep learning architecture from the perspective of NLP.
Basic input-output structure:
b. many inputs and one output from last one
a. An RNN can simultaneously take a sequence of inputs and produce a sequence of outputs. For example, this type of network is useful for predicting time series such as stock prices: you feed it the prices over the last N days, and it must output the prices shifted by one day into the future
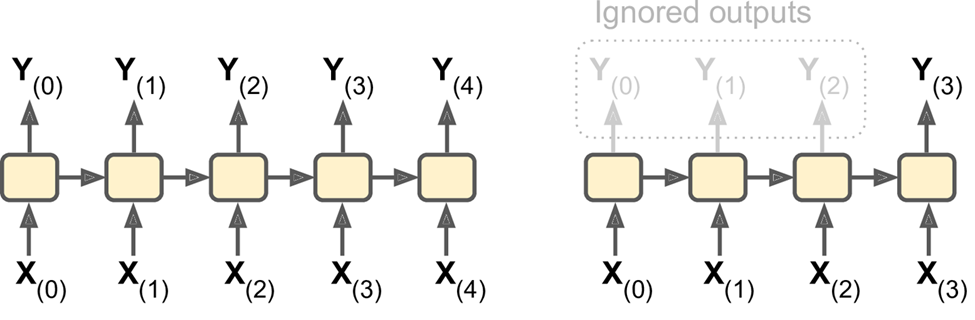
b. Alternatively, you could feed the network a sequence of inputs, and ignore all outputs except for the last one (see the top-right network). In other words, this is a sequence-to-vector network. For example, you could feed the network a sequence of words corresponding to a movie review, and the network would output a sentiment score (e.g., from –1 [hate] to +1 [love]).
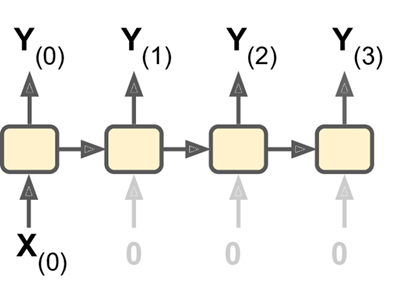
c. Conversely, you could feed the network a single input at the first time step (and zeros for all other time steps), and let it output a sequence (see the bottom-left network). This is a vector-to-sequence network. For example, the input could be an image, and the output could be a caption for that image.
There are different types of sequence to sequence deep learning structures
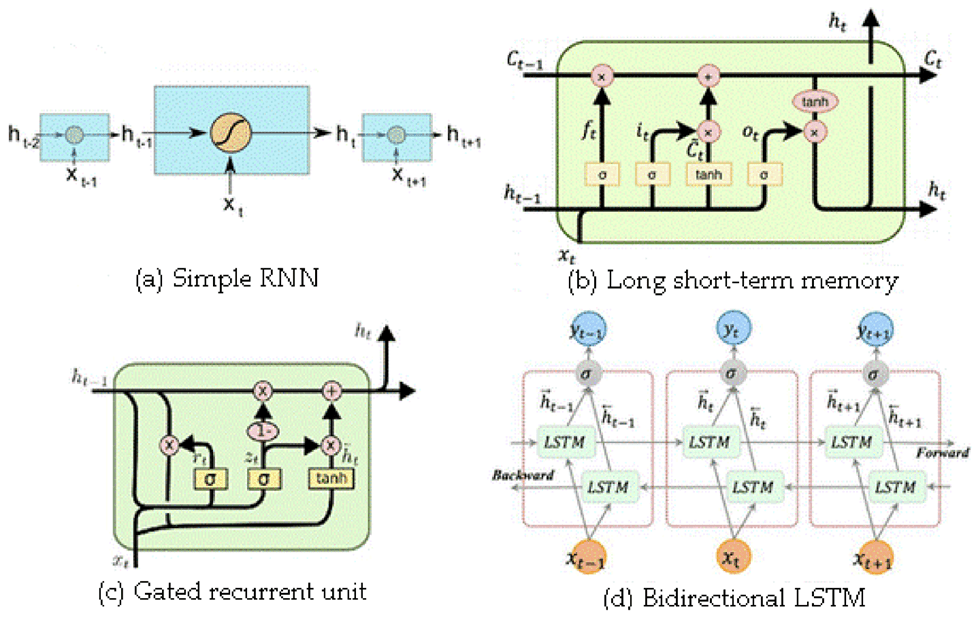
a. Recurrent Neural Networks (RNNs)
RNNs have feedback loops in the recurrent layer. This lets them maintain information in ‘memory’ over time. But, it can be difficult to train standard RNNs to solve problems that require learning long-term temporal dependencies.
This is because the gradient of the loss function decays exponentially with time (called the vanishing gradient problem).
b. Long Short-Term Memory (LSTM)
LSTM networks are a type of RNN that uses special units in addition to standard units. LSTM units include a ‘memory cell’ that can maintain information in memory for long periods of time. This memory cell lets them learn longer-term dependencies.
LSTMs deal with vanishing and exploding gradient problem by introducing new gates, such as input and forget gates, which allow for a better control over the gradient flow and enable better preservation of “long-range dependencies”.
𝐍𝐨𝐭𝐞: The long range dependency in RNN is resolved by increasing the number of repeating layer in LSTM.
c. Gated Recurrent units (GRU)
The GRU has two gates, LSTM has three gates. GRU does not possess any internal memory, they don’t have an output gate that is present in LSTM
In LSTM the input gate and target gate are coupled by an update gate and in GRU reset gate is applied directly to the previous hidden state. In LSTM the responsibility of reset gate is taken by the two gates i.e., input and target.
d. Bidirectional LSTM
A Bidirectional LSTM, or biLSTM, is a sequence processing model that consists of two LSTMs: one taking the input in a forward direction, and the other in a backwards direction. BiLSTMs effectively increase the amount of information available to the network, improving the context available to the algorithm (e.g. knowing what words immediately follow and precede a word in a sentence).
e. Stacked bidirectional LSTM
Many bidirectional LSTMs are stacked together
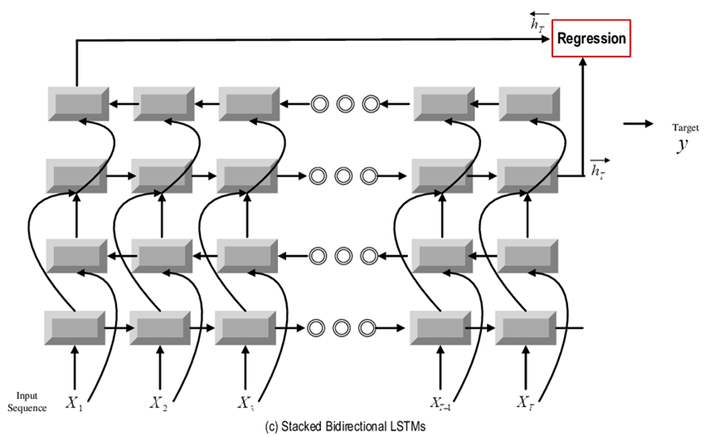
f. Encoder Decoder models
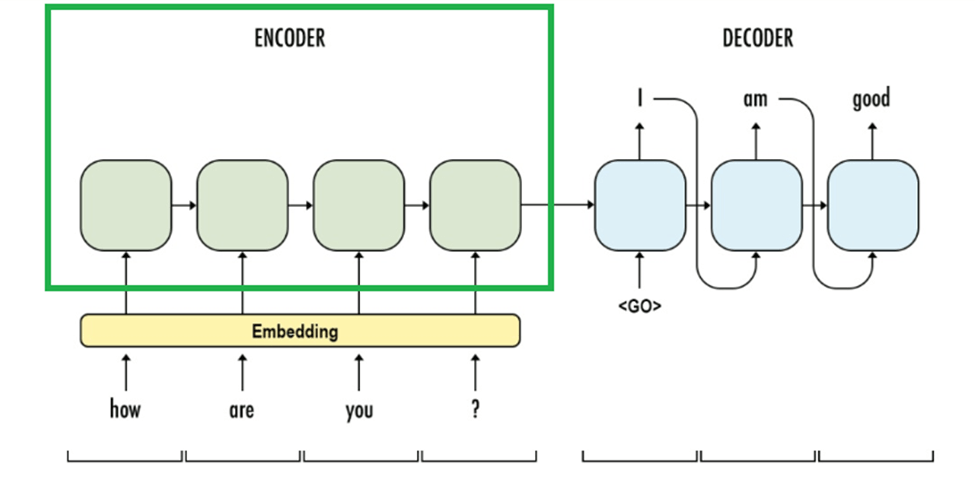
Single context vector from the last encoder cells is fed to the decoder.
Problems with Encoder Decoder models
1.) We need to bring down sentences of source Input into fixed length vector where This may lead to difficulty in handling long sentences resulting in loosing Information or We can also says that loosing context information instead we having Bi-directional RNN-LSTM cells.
2.) If We have test sentences longer than training corpus that basically reducing the performance as length of input sentences increases.
3.) Context of all Encoder RNN cells is consolidated and Output of Last Cell of Encoder have feeded to Decoder’s first RNN Cells therefore Model not clearly able to understand which are the most significant words to predict target word.
To Overcome this Issue, An Attention cames into picture where we are trying to find out which of Input words of given sentence are responsible for generating each target output word.
Idea to solve this issue, Researchers came up with an Idea in 2016, to add a Neural Network between Encoder and Decoder which is responsible for finding out the most significant words or we can say focused words of Input Sentence to predict target output to achieve the concept of Attention or Self-Attention
g. Encoder -Decoder with Self-Attention
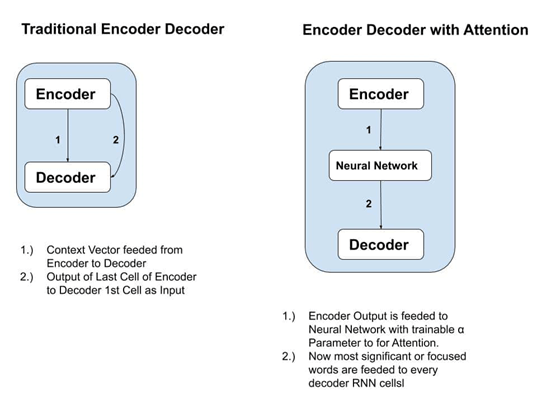
The outputs which are generated from Encoder Cells is the Input for the intermediate neural network with trainable parameter is alpha value denoted as { α }.So context vector denoted as { C } which is computed as weighted sum of Outputs of Encoder cells with Trainable alpha value .This equation depicts like basic neural network equation.
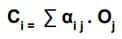
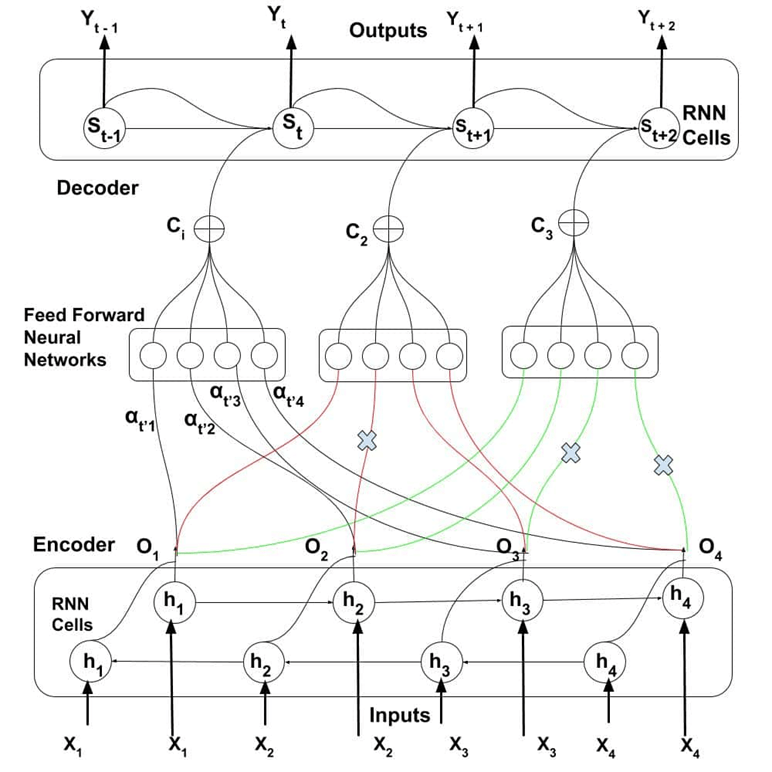
h. Attention Mechanism (Transformers) – Attention is all you need (Research paper) & Jay Alammer’s Blog
Encoder-Decoder stacks (Transformer model architecture)
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder
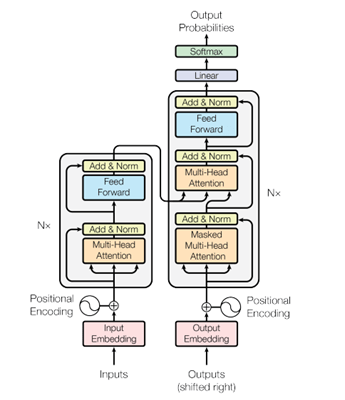
In this architecture, encoder is represented on the left side box and decoder is represented in the right side box. To understand this better, go through the below attention mechanism.
Attention:
Refer Jay Alammer’s Blog for detailed explanation
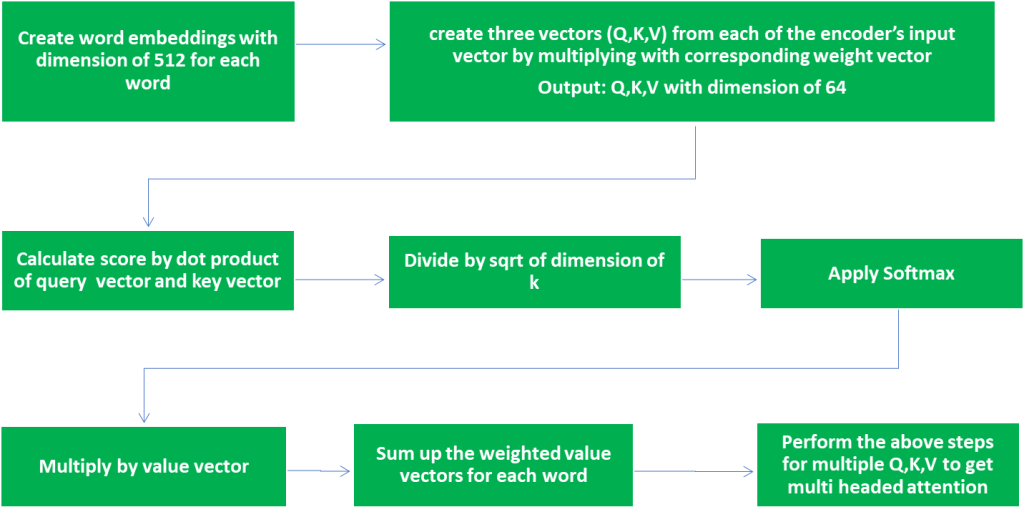
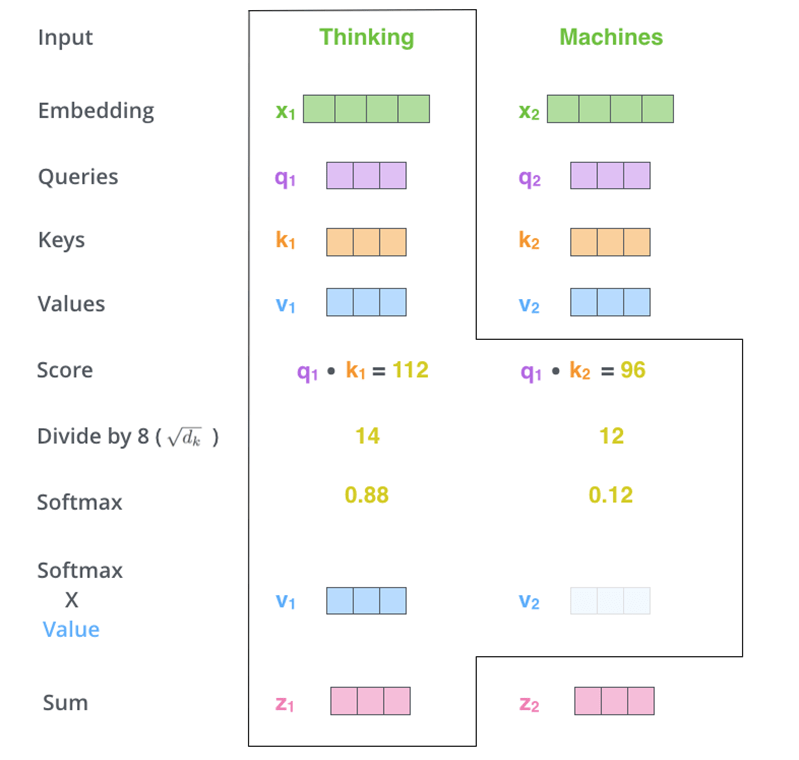
Attention(Q, K, V ) = softmax(Q *KT /√dk)V
Multi-head attention
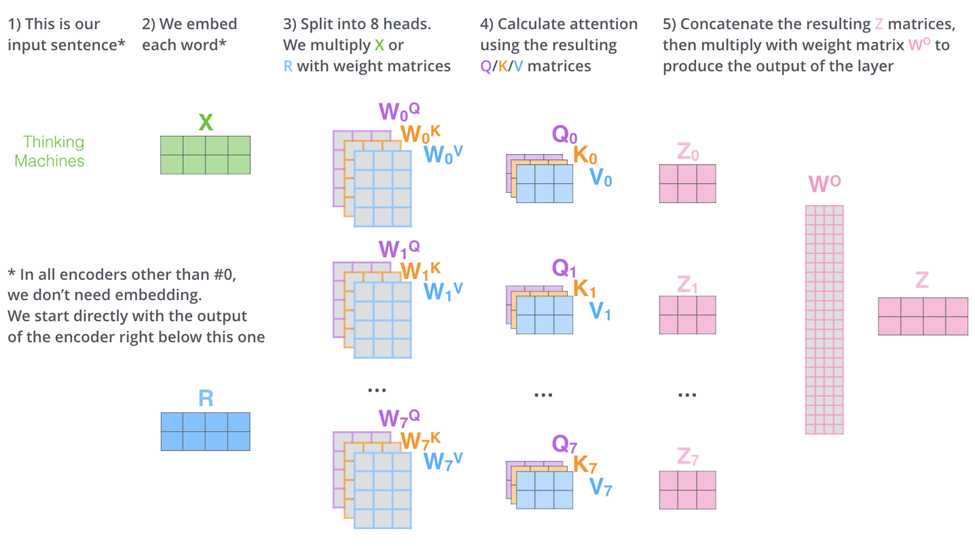
Positional encoding
Since there is no re-occurrence and no convolution, position of the tokens are important. One thing that’s missing from the model is the order of the words in the input sequence.
To address this, the transformer adds a vector to each input embedding. These vectors follow a specific pattern that the model learns, which helps it determine the position of each word, or the distance between different words in the sequence. The intuition here is that adding these values to the embeddings provides meaningful distances between the embedding vectors once they’re projected into Q/K/V vectors and during dot-product attention.
Pre-Trained models
A pre-trained model is a saved network that was previously trained on a large dataset
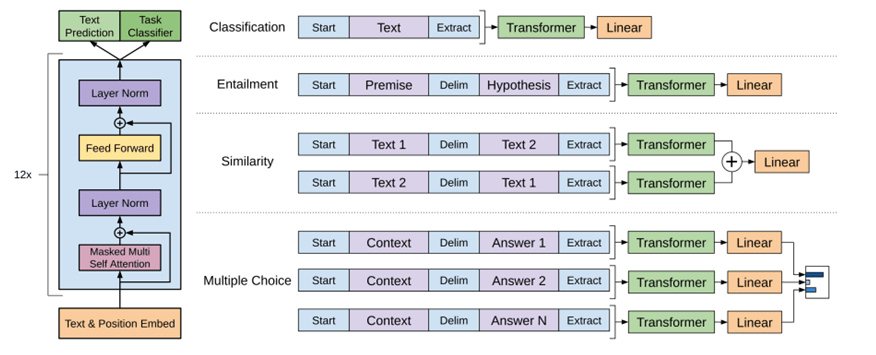
a. GPT-1 / GPT-2 (Generative Pre-Trained Transformers)
Both GPT-1 and GPT2 are decoder based models. GPT is a Transformer-based architecture and training procedure for natural language processing tasks. Training follows a two-stage procedure. First, a language modeling objective is used on the unlabeled data to learn the initial parameters of a neural network model. Subsequently, these parameters are adapted to a target task using the corresponding supervised objective.
GPT-2 is a large transformer-based language model with 1.5 billion parameters, trained on a dataset of 8 million web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some text. It largely follows the previous GPT architecture with some modifications:
- Layer normalization is moved to the input of each sub-block, similar to a pre-activation residual network and an additional layer normalization was added after the final self-attention block.
- A modified initialization which accounts for the accumulation on the residual path with model depth is used. Weights of residual layers are scaled at initialization by a factor of 1/N where N is the number of residual layers.
- The vocabulary is expanded to 50,257. The context size is expanded from 512 to 1024 tokens and a larger batch size of 512 is used.
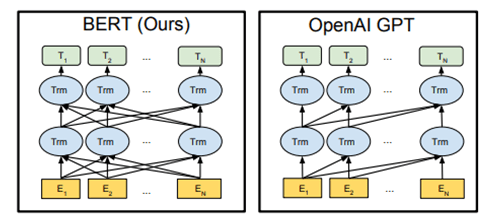
b. BERT (Bi-directional Encoder Representation from Transformers)
Bidirectional Encoder Representations from Transformers
The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked
use a “next sentence prediction” task that jointly pretrains text-pair representations
During pre-training, the model is trained on unlabeled data over different pre-training tasks. For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks
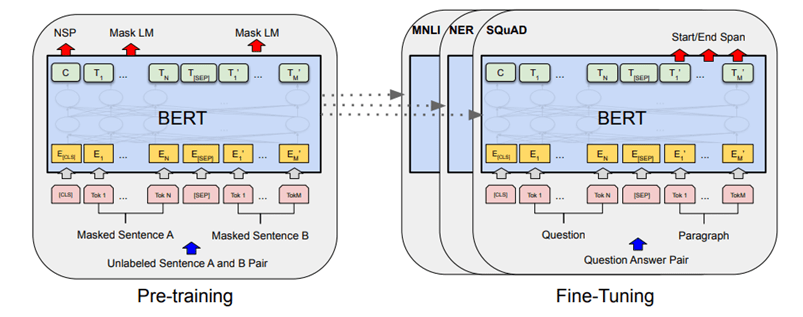
The model must predict the original sentence, but has a second objective: inputs are two sentences A and B (with a separation token in between). With probability 50%, the sentences are consecutive in the corpus, in the remaining 50% they are not related. The model has to predict if the sentences are consecutive or not.
The library provides a version of the model for language modeling (traditional or masked), next sentence prediction, token classification, sentence classification, multiple choice classification and question answering.
BERT vs GPT Comparison:
| Area | GPT | BERT |
| Encoder / Decoder | Decoder only model | Encoder only model |
| Direction | Unidirectional (left to right transformer) | Bidirectional transformer |
| Input | One sentence as input | two sentence pair as input during Pre-training. One/Two sentence as input during fine-tuning depending on the tasks / use case |
| Masking | Masking at the input word level, words are randomly masked | masking right side of the data during multi-head attention |
c. ALBERT (Research Paper)
Two parameter reduction techniques to lower memory consumption and increase the training speed of BERT. Use a self-supervised loss that focuses on modeling inter-sentence coherence, and show it consistently helps downstream tasks with multi-sentence inputs
There are three main contributions that ALBERT makes over the design choices of BERT.
- Factorized embedding parameterization
- Cross-layer parameter sharing
- Inter-sentence coherence loss
d. DIstillBert: Research Paper
Same as BERT but smaller. Trained by distillation of the pretrained BERT model, meaning it’s been trained to predict the same probabilities as the larger model. The actual objective is a combination of:
- finding the same probabilities as the teacher model
- predicting the masked tokens correctly (but no next-sentence objective)
- a cosine similarity between the hidden states of the student and the teacher model
Leverage knowledge distillation during the pre-training phase and show that it is possible to reduce the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster. To leverage the inductive biases learned by larger models during pre-training, we introduce a triple loss combining language modeling, distillation and cosine-distance losses.
While GPT used a standard language modeling objective which predicts the next word in a sentence, BERT was trained on Masked Language Modeling (MLM) and Next Sentence Prediction (NSP). The RoBERTa model replicated the BERT model architecture but changed the pre-training using more data, training for longer, and removing the NSP objective
Encoder-Decoder based models:
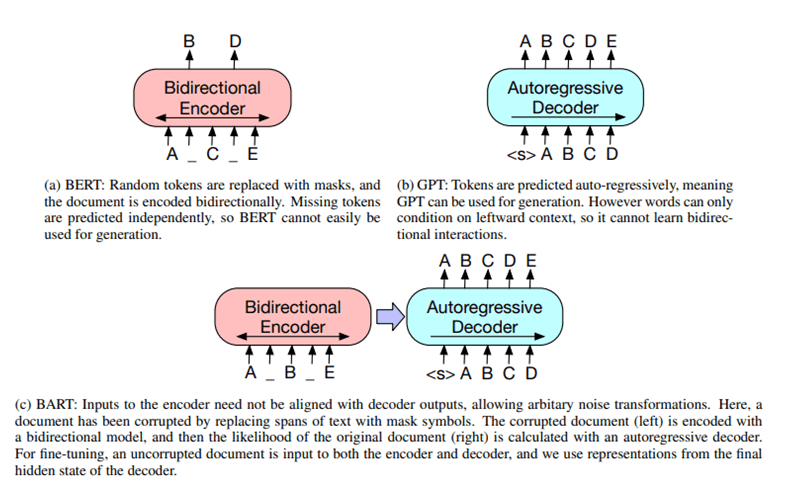
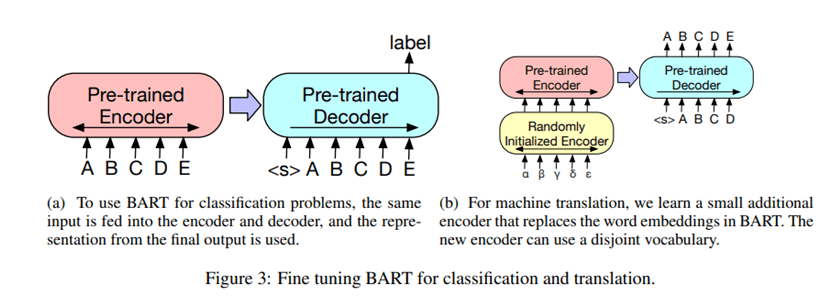
a. BART (Research Paper)
BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text
Sequence-to-sequence model with an encoder and a decoder. Encoder is fed a corrupted version of the tokens, decoder is fed the original tokens (but has a mask to hide the future words like a regular transformers decoder). A composition of the following transformations are applied on the pretraining tasks for the encoder:
- mask random tokens (like in BERT)
- delete random tokens
- mask a span of k tokens with a single mask token (a span of 0 tokens is an insertion of a mask token)
- permute sentences
- rotate the document to make it start at a specific token
pre-trains a model combining Bidirectional and Auto-Regressive Transformers. BART is a denoising autoencoder built with a sequence-to-sequence model that is applicable to a very wide range of end tasks. Pretraining has two stages (1) text is corrupted with an arbitrary noising function, and (2) a sequence-to-sequence model is learned to reconstruct the original text.
b. mBART (Research Paper)
The model architecture and pretraining objective is same as BART, but MBart is trained on 25 languages and is intended for supervised and unsupervised machine translation. MBart is one of the first methods for pretraining a complete sequence-to-sequence model by denoising full texts in multiple languages
c. MarianMT (Research Paper)
A framework for translation models, using the same models as BART
d. Pegasus (Research Paper)
Sequence-to-sequence model with the same encoder-decoder model architecture as BART. Pegasus is pre-trained jointly on two self-supervised objective functions: Masked Language Modeling (MLM) and a novel summarization specific pretraining objective, called Gap Sentence Generation (GSG).
- MLM: encoder input tokens are randomly replaced by a mask tokens and have to be predicted by the encoder (like in BERT)
- GSG: whole encoder input sentences are replaced by a second mask token and fed to the decoder, but which has a causal mask to hide the future words like a regular auto-regressive transformer decoder.
In contrast to BART, Pegasus’ pretraining task is intentionally similar to summarization: important sentences are masked and are generated together as one output sequence from the remaining sentences, similar to an extractive summary.
e. T5 (Research Paper) – Text-To-Text Transfer Transformer
T5 uses the traditional transformer model (with a slight change in the positional embeddings, which are learned at each layer). To be able to operate on all NLP tasks, it transforms them into text-to-text problems by using specific prefixes: “summarize: ”, “question: ”, “translate English to German: ” and so forth.
The pretraining includes both supervised and self-supervised training. Supervised training is conducted on downstream tasks provided by the GLUE and SuperGLUE benchmarks (converting them into text-to-text tasks as explained above).
Self-supervised training uses corrupted tokens, by randomly removing 15% of the tokens and replacing them with individual sentinel tokens (if several consecutive tokens are marked for removal, the whole group is replaced with a single sentinel token). The input of the encoder is the corrupted sentence, the input of the decoder is the original sentence and the target is then the dropped out tokens delimited by their sentinel tokens.
For instance, if we have the sentence “My dog is very cute .”, and we decide to remove the tokens: “dog”, “is” and “cute”, the encoder input becomes “My <x> very <y> .” and the target input becomes “<x> dog is <y> cute .<z>”
GPT-3 (Research Paper)
- The GPT-3 model uses the same model and architecture as GPT-2, including the modified initialization, pre-normalization, and reversible tokenization.
- However, in contrast to GPT-2, it uses alternating dense and locally banded sparse attention patterns in the layers of the transformer, as in the Sparse Transformer.
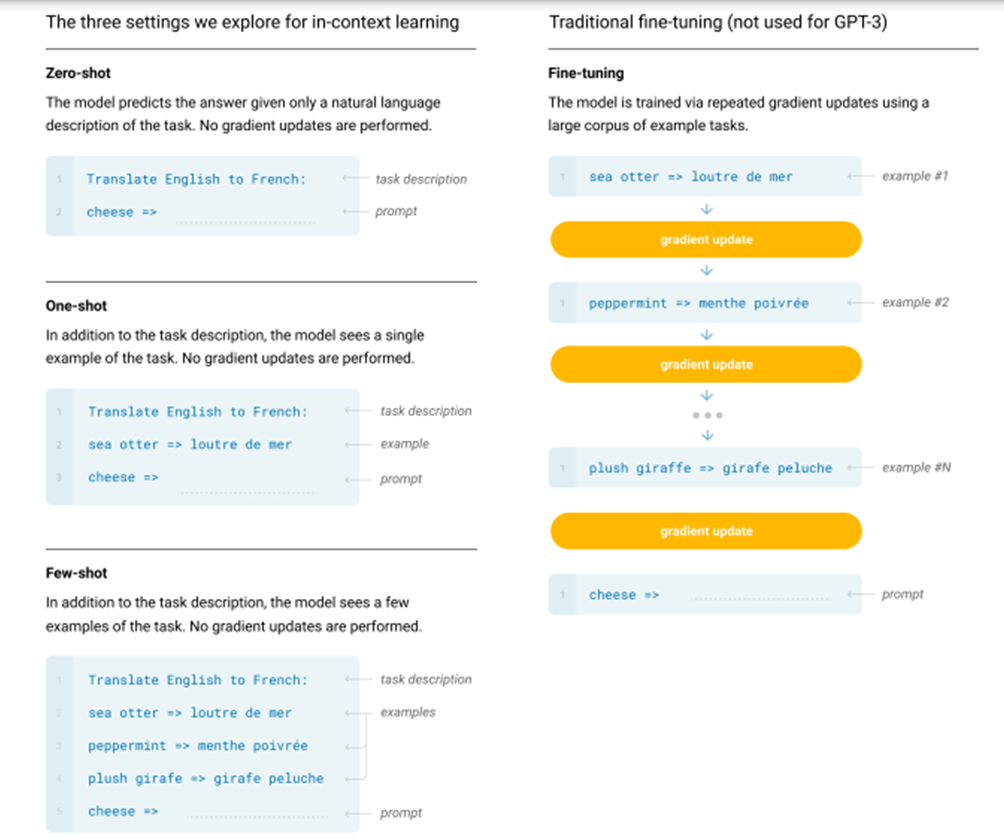
- The model is evaluated in three different settings:
- Few-shot learning, when the model is given a few demonstrations of the task (typically, 10 to 100) at inference time but with no weight updates allowed.
- One-shot learning, when only one demonstration is allowed, together with a natural language description of the task.
- Zero-shot learning, when no demonstrations are allowed and the model has access only to a natural language description of the task.
Model use from Huggingface
Huggingface Transformers provides the following tasks out of the box:
- Sentiment analysis: is a text positive or negative?
- Text generation (in English): provide a prompt and the model will generate what follows.
- Name entity recognition (NER): in an input sentence, label each word with the entity it represents (person, place, etc.)
- Question answering: provide the model with some context and a question, extract the answer from the context.
- Filling masked text: given a text with masked words (e.g., replaced by
[MASK]), fill the blanks. - Summarization: generate a summary of a long text.
- Translation: translate a text in another language.
- Feature extraction: return a tensor representation of the text.
Example pipeline code:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I hate you")[0]
print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: NEGATIVE, with score: 0.9991
result = classifier("I love you")[0]
print(f"label: {result['label']}, with score: {round(result['score'], 4)}"),
label: POSITIVE, with score: 0.9999Sample steps to use huggingface transformers
a. Select tokenizer and pre-trained model as per use case
Refer to https://huggingface.co/docs/transformers/model_summary and choose the pre trained model.
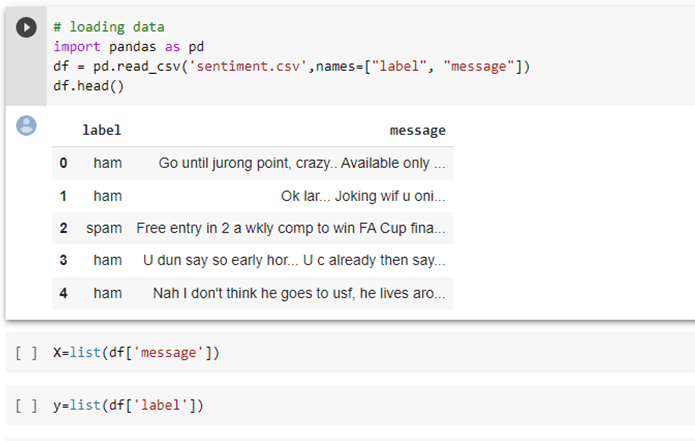
b. Prepare your dataset
c. Tokenization
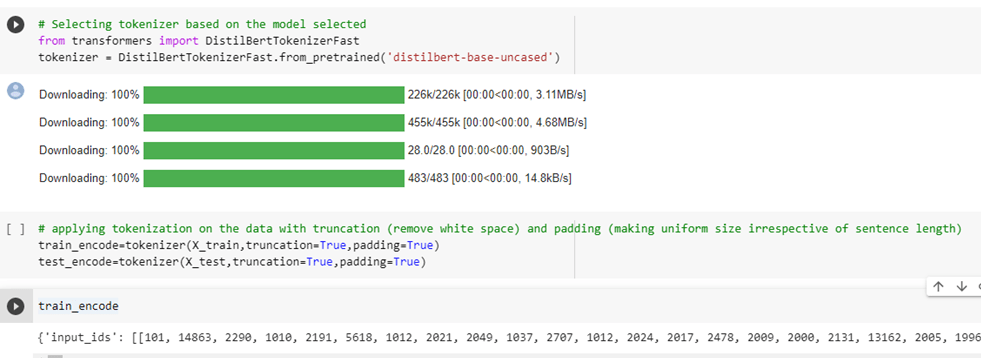
d. convert encoding to dataset objects
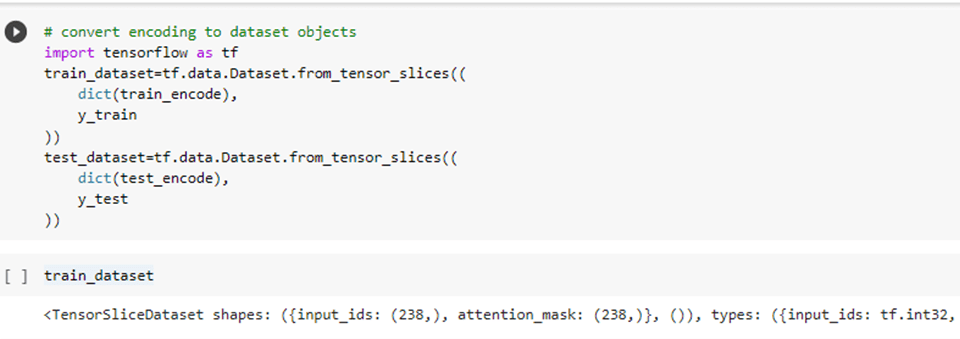
e. Train (fine-tune model)
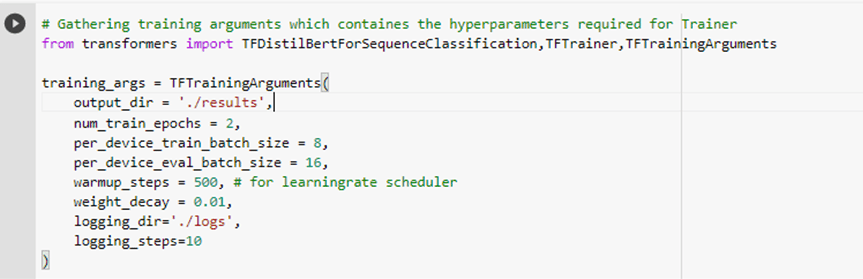
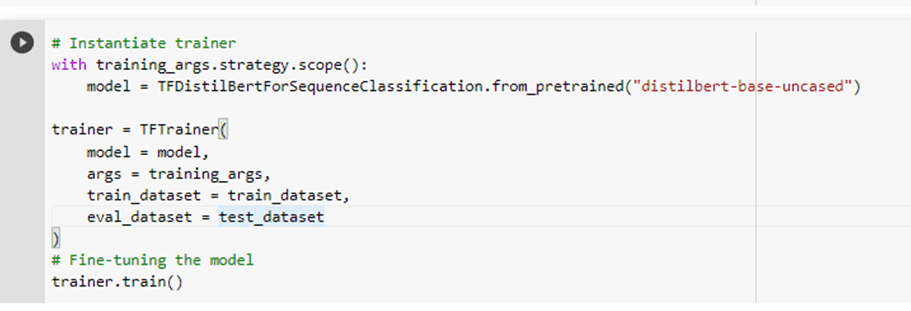
f. Evaluate and save the model for deployment
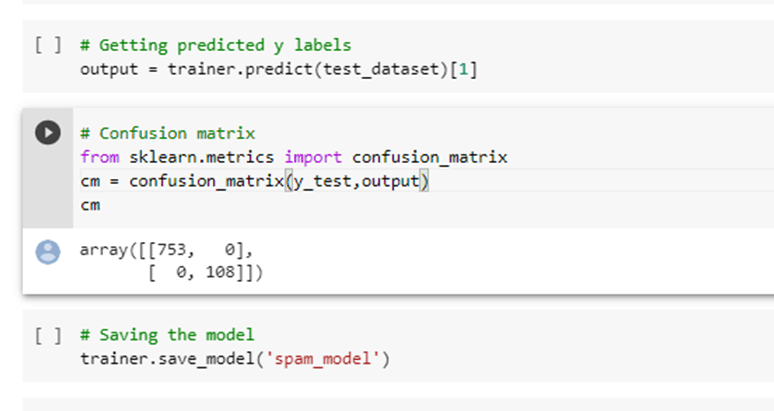
Fine-tuning:
Fine-tuning is a process that takes a model that has already been trained for one given task and then tunes or tweaks the model to make it perform a second similar task.
Types of fine-tuning
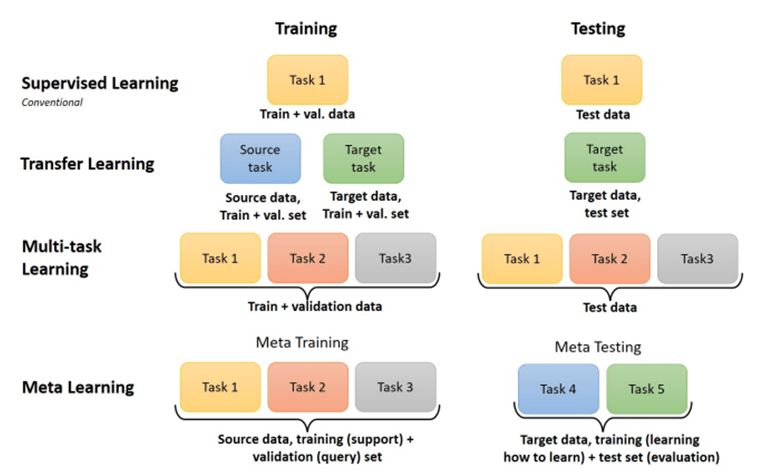
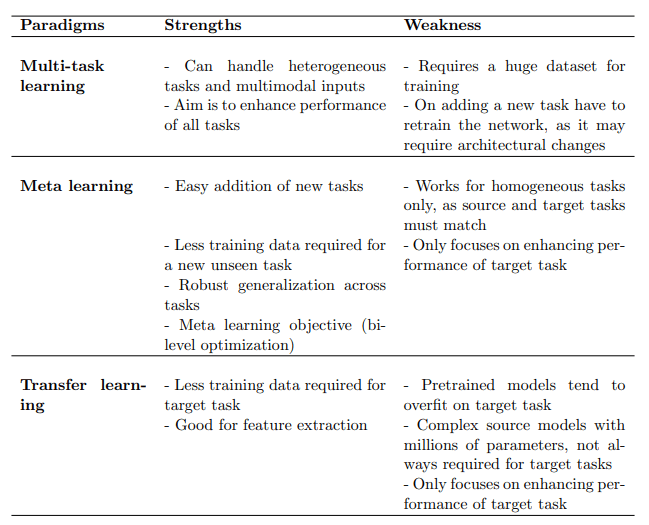
Transfer Learning: Most ML models work under the assumption that the training and testing data are drawn from the same distribution (domain). If the distribution is changed, then the model needs to be trained again from scratch. Transfer learning helps to overcome this issue. Transfer learning refers to exploiting what has already been learned in one setting to improve the learning in another setting Goodfellow et al. (2016). Information transfer happens from the source domain (transfers knowledge to other tasks) to the target domain (use knowledge from other tasks).
Multi-Task Learning is an inductive transfer approach that exploits the
domain information in the training data of related tasks as inductive bias to improve the
generalization of all the tasks. The underlying theory of MTL is, the information gained
while learning one task can help the other task to learn better. In MTL all the tasks
are trained (or learned) together, Maurer et al. (2016) explains that shared representations significantly improve the performance of the tasks as compared to learning task individually.
Meta Learning better known as “Learning to learn” is a learning paradigm that aims to improve the learning of new tasks with lesser data and computation, by exploiting the experience gained over multiple training episodes for various tasks.
The conventional ML algorithm employs multiple data instances for better model predictions, while meta learning uses multiple learning instances to improve the performance of a learning algorithm.
Further Explanation
